全部
资讯
产品
关注微信
关注微博
新闻头条
军桥杂志
首页
国防信息化
智慧军营
通讯指挥
大屏显控
虚拟仿真
信息安全
AI计算
安防监控
无人机
作训装备
数码物联
军工电子
媒体展会
方案
技术
热点
产品
无人机模拟训练
联合作战
指控中心
智能枪弹柜
智慧军营
野战兵器室
账外机
手机管控
电子沙盘
军事体育训练
智慧训练
数字化营区
无线通信
Mesh自组网
战术训练
虚拟训练
仿真训练
更多
AI计算
|
技术方案
|
行业资讯
|
AI算力产品
首页
>
AI计算
>
行业资讯
> 正文
突破性能极限,阿里云神龙最新解读
2020-03-17 17:05:29
来源:阿里云神龙团队
日前,ASPLOS 2020公布了计算机界最新科技成果,其中包括阿里云提交的名为《High-density Multi-tenant Bare-metal Cloud》的论文,该论文阐述了阿里云自研的神龙服务器架构如何解决困扰云计算行业多年的虚拟化性能损耗问题,打破物理机的性能神话,让云服务器突破性能极限。
虚拟化是云计算的基石,多租户(Virtual Machines)共享一个物理服务器,提高了数据中心服务器的利用率,使得云计算服务商可以提供更经济高效的服务。但是,虚拟化下多VM共享物理服务器的技术会引入不少安全问题,尤其是最近的侧通道攻击等。此外, CPU、内存和 I/O 在虚拟化性能方面会产生不可忽略的开销。为此,物理服务器租赁已成为公共云中新兴的服务类型,物理服务器租赁为用户提供了强大的隔离性、对硬件的全面和直接访问以及更可预测的性能。但是物理服务器租赁的方式也有其缺点:它只能针对单租户,且不具备可扩展性、成本又高,适应性弱。当前物理服务器租赁只能将整个物理服务器租给单个用户,并且在租用服务器后用户无法方便的替换镜像,存储等云计算的基本服务。
在本文中,我们提出了一种创新的高密度多租户共享弹性裸金属服务器的设计,也就是阿里云神龙弹性裸金属架构(论文中为了满足评审的要求称为BM-Hive)。在阿里云神龙高密裸金属架构中,每个裸金属实例都运行在一个单独设计的计算子板上,该计算子板带有专有的 CPU 和内存模块。BM-Hive为每个计算子板配备了硬件/软件混合 virtio I/O 系统,使客户实例能够直接访问阿里云网络和存储服务。BM-Hive 可在单个物理服务器中托管多达 16 个裸金属实例,显著提高裸金属服务器的实例密度。此外,BM-Hive 在硬件级别严格隔离每个裸金属实例,以提高安全性和隔离性。神龙弹性裸金属高密方案已经在阿里云的公共云部署。它目前同时为百万级用户提供服务。
介绍
物理服务器租赁的出现是为了满足对性能或者安全性有非常苛刻要求的客户。但对于单租户,低密度的物理服务器却存在成本高的问题。公共云上面的大多数客户是中小规格客户。我们统计云服务上面的各个规格的VM的vCPU数量,对于需求小于32Core 的VM占到了95%以上。而现有物理服务器的CPU规格最小也有64Core,最高达到128Core。这些中小客户别无选择,要么放弃物理机级别的性能与安全性,采用传统虚拟化的VM,要么租赁整个服务器,而放弃性价比。这也是不具备弹性的裸金属公共云尚未成为主流的重要原因之一。
为此,我们设计了神龙高密度弹性裸金属架构:一个可扩展的,支持多租户的弹性裸金属硬件虚拟化方案。该裸金属框架(BM-Hive)既能保证CPU和内存拥有本地物理机运行时的性能,又实现IO设备的硬件虚拟化,同时具备云计算的分钟级计费、弹性扩容等最重要功能。BM-Hive由三个模块组成:计算子板,IO-Bond,BM-hypervisor。计算子板包含了可替代的裸金属实例的CPU与内存;BM-hypervisor运行在我们的基础物理服务器上,它可以托管最大16个计算子板;IO-Bond是连接计算子板与BM-Hypervisor的纽带。我们在后续章节将会详细介绍这三个部分。
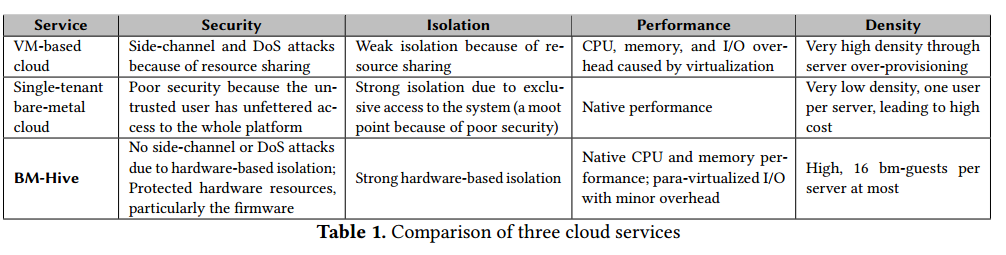
采用BM-Hive的方案显著优点:
• 经济实惠:采用了高达16个裸金属实例共享一个物理服务器,能显著降低客户成本;
• 单线程性能优异:裸金属实例可以自由采用高主频CPU,比如i7 4.2GHz;
• 兼容当前运维体系:客户可以像使用其他非裸金属实例一样操作裸金属实例,包括制作镜像、更换系统盘、添加/删除云盘等云计算特有便捷操作。
对比当前公共云上多种不同实例优劣如下:
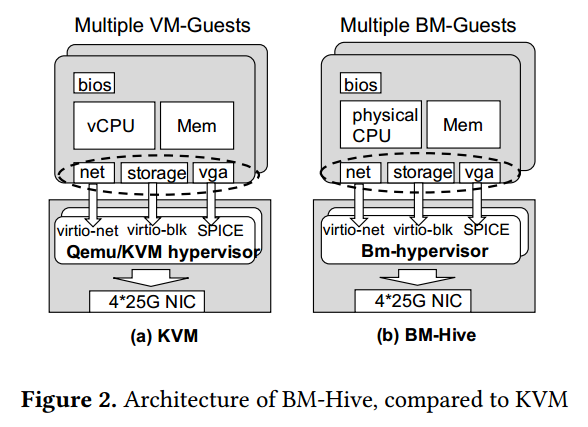
神龙裸金属架构是软硬一体化的虚拟化架构
神龙裸金属软硬一体虚拟化架构是对现有虚拟化的一个自然演进与升级换代。入下图所示,在整体架构上面,BM-Hive与传统虚拟化方案在CPU/内存方面、运维体系接入、多租户复用等方面非常相近。神龙裸金属开发了一套适合裸金属共享方案的软硬件一体BM-Hypervisor来处理计算子板的IO子系统。
当前虚拟化主要面临如下问题:
在详细探讨神龙裸金属架构之前,我们先来看看当前云计算虚拟化面临的一些问题。而神龙裸金属软硬一体虚拟化方案很好的解决了这些问题。
• 虚拟化开销无法满足高性能需求
• 虚拟化性能存在无法控制的抖动,从而无法满足对性能极致要求的场景
• 虚拟化的安全隔离性达不到特定行业要求
• 嵌套虚拟化的性能无法满足客户需求
虚拟化开销:
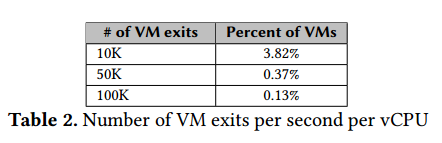
当前虚拟化的基本原理决定了CPU必须要在vCPU环境与物理CPU环境下来回切换(VM-Exit)。频繁的切换会导致严重的VM性能问题。比如一个典型的直通设备中断,在虚拟化下处理流程就非常长。KVM hypervisor下面一个虚拟化切换至少需要几千个时钟周期,开销有可能会达到~10us。一般情况下VMExit(比如中断)达到5K左右,VM的性能将开始受影响。还有各种原因导致的VMExit,比如IPI,EPT violation,MMIO访问,等等。
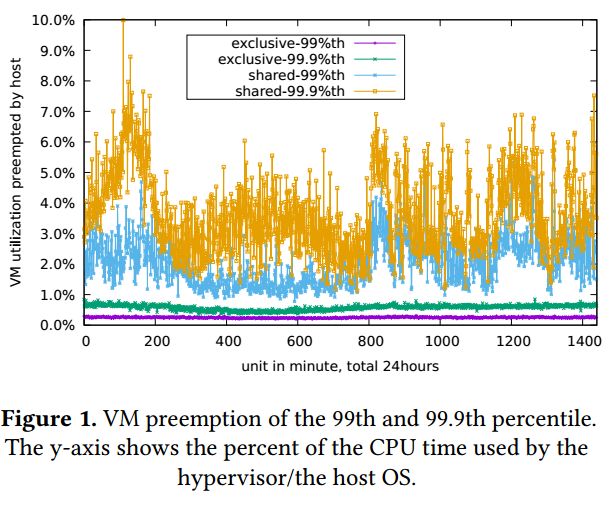
我们采样了30万个虚拟化实例的运行数据,发现每秒1万次以上VM-Exit的实例达到3.82%,甚至还有不少每秒超过10万切换的实例。
神龙裸金属BM-Hive由于采用了计算子板直接运行实例,避免了任何传统CPU/内存虚拟化的开销。
虚拟化的性能抖动:
由于客户实例与系统服务都共享同一个CPU,这就导致了当宿主机系统服务繁忙时可能影响到客户实例的运行。我们采样了2万个实例在运行中CPU被抢占的情况,发现在共享性实例上,有200个以上的实例,在运行中被系统占用的CPU利用率超过2%。也就是说这200个实例的实际CPU性能是98%而不是100%,同样的情况在独享型的实例也有发生。毕竟中断等处理是一定需要CPU在宿主机系统中才能处理的。而在BM-Hive下的实例,系统服务在BM-hypervisor下运行,与计算子板的CPU为不同的物理CPU,所以神龙裸金属实例根本就不存在任何抢占计算资源的问题。
虚拟化的安全性:
这个不是一个新问题,我们都承认安全级别从低到高的形态:进程->容器->虚拟化->物理机。今年发生的侧信道攻击等都说明,虚拟化下实例并非牢不可破。而神龙裸金属实例运行在独立的计算子板之上,是天然的物理隔离,不存在这些安全问题
嵌套虚拟化性能问题:
一般来说KVM嵌套虚拟化的性能损失在20%以上,尤其是遇到一些IO操作更频繁的场景。因此当前云计算实例上很难在满足客户二次虚拟化的要求。而神龙裸金属实例却可以运行客户在实例内部再次运行他们自己喜欢的各种硬件加速的虚拟化方案。
神龙裸金属架构系统设计
为了解决传统虚拟的诸多问题,BM-Hive的设计考虑目标为:
• 多租户
• 物理机隔离安全性
• 接入现有运维体系
• 物理机性能
• 低成本
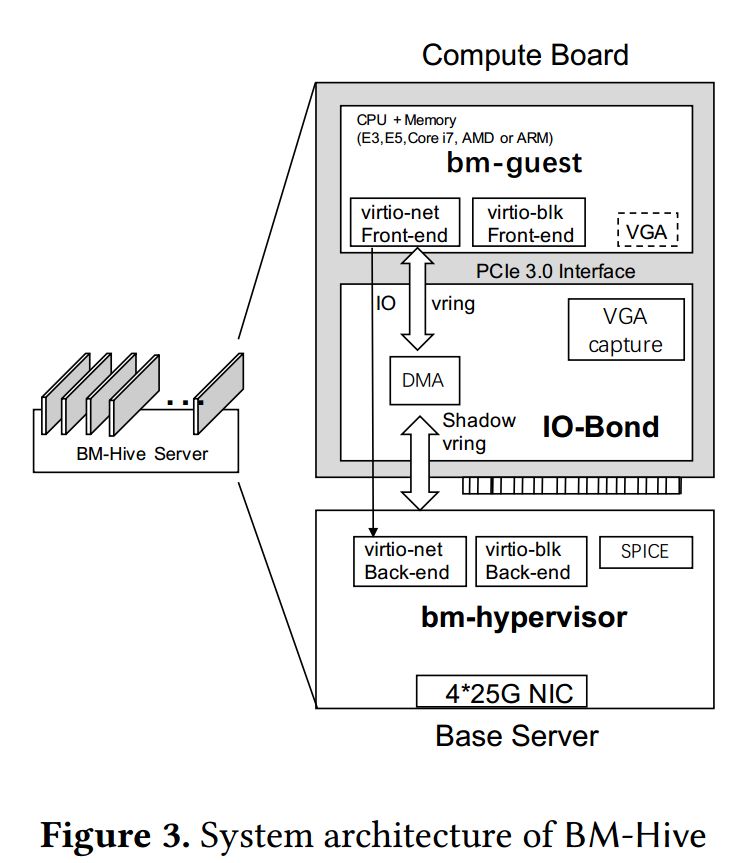
图3显示了BM-Hive的整体系统架构。我们把神龙裸金属实例称为:BM-guest。把基于传统虚拟化的实例称为:VM-guest。每个裸机服务器由底座和多个计算子板构成。该底座本质上是一个简化的基于 Xeon 的服务器。每个计算子板都有一个PCIe 扩展板连接到底座。其主要组件包括 CPU、内存、PCIe 总线和 IO-Bond。IO-Bond 是用FPGA实现的硬件接口。它连接底座和计算子板的PCIe总线,功能类似与PCIe的透明桥功能。IO-Bond在计算子板的PCIe总线上,它模拟多个virtio设备并由标准virtio内核驱动程序支持。IO-Bond充当bm-guest/virtio前端与后端BM-Hypervisor的桥梁。目前,IO-Bond 支持 virtio 设备网络和存储(块设备)。它可以很容易地扩展支持其他virtio设备。
一些思考
IO-Bond的性能优化:IO-Bond处于IO系统的关键性能路径之上。当前由FPGA实现。在将来我们可以通过ASIC芯片的方式实现,从而进一步提升网络与存储、性能
热迁移与热升级:热升级在裸金属实例上面是可以实现的。我们在升级底座BM-Hypervisor的同时可以做到对客户实例无感知。我们在2019年ASPLOS的论文中就有详细介绍实例热升级的技术《 Fast and Scalable VMM Live Upgrade in Large Cloud Infrastructure 》 。热迁移理论上,裸金属实例也可以实现,我们做过一些尝试。目前也正在开发中。
SGX支持:SGX的支持在裸金属实例上面没有任何问题。相反由于去掉了虚拟化的阻碍,SGX的支持更容易。
关键词:
阿里云
云计算
虚拟化
软硬一体
上一篇:
震撼狂测!超坚韧的Getac强固电脑
下一篇:
Getac V110 帮助泰晤士水务公司高效进行现场服务
索取“此产品”详细资料,请留言
*姓名:
*手机:
*邮寄地址:
相关阅读
云计算发展瓶颈显现该如何破解
如何实现云计算时代的数据备份
云时代,如何才能有效解决云计算安全问题!
如何在云计算中使用虚拟磁盘?
在云计算数据基础上构建技术层
开源模式下的云计算和大数据现状
大数据引发混合云井喷 四大场景与三大技术
拟态分布式文件存储设备
大数据技术,发展趋势如何?
混合云大势所趋,开源是最好的创新模式
热点文章
本地私有化部署AI大模型
1
国产化替代批量信创终端面临“管控、运维”难问题的解析及攻略
2
清华同方加固亮相 “第十一届中国国际国防电子展览会”
3
宝易加固CPCI计算机在海军舰载多功能显控台的应用
4
深信服|涉密虚拟化解决方案
5
联想加固机全系产品亮相2018第十一届中国国际国防电子展
6
军用加固计算机的特点及技术方向
7
拟态分布式文件存储设备
8
个人特种计算机在军事行动中的作用
9
松下发布新型加固笔记本touchbook S9
10
飞龙 智胜 金刚 申泰齐亮相 超越数控盛装国防电子展
热点方案
Durabook Z14I军用级强固式笔记本——为定制化带来无限可能
半加固规格的DURABOOK S14I半加固笔记本电脑
宝易加固CPCI计算机在海军舰载多功能显控台的应用
深信服|涉密虚拟化解决方案
军用加固计算机的特点及技术方向
个人特种计算机在军事行动中的作用
YANSEN元存宽温SSD应用于军用加固计算机解决方案
麒麟信安“一云多芯”国产化云解决方案
抗核幅照计算机的研究现状
Durabook Z14I军用级强固式笔记本——为定制化带来无限可能
国产求解器在大规模复杂场景的应用, 为军事资源管理调度优化带来新启示
加固机的发展及其在军用领域的应用
产品推荐
卫星通信加密系统
网翎便捷式卫星上网机
ZL60P-E 折叠一体化卫星宽带自动便携终端
AB330S便携双极天线 AB230S便携三线天线
融讯RX ESW64专线保障切换器(专业版)
集群快速部署小站系统Rapid