2020-03-20 10:17:53
来源:深信服科技
海量数据时代来临,但在这上空飘着一朵乌云——那就是海量小文件的存储问题。
海量小文件是怎么产生的?
海量小文件:业内通常将大小在1MB以内的文件称为小文件,百万级数量及以上称为海量,由此量化定义海量小文件。
首先我们来看一下海量小文件是怎么产生的?
人工智能、物联网、智慧金融、智能安防、传感器网络、科学实验等应用的发展产生了大量数据,这些数据种类繁多,大小不一。不仅包括海量的大文件(大于1MB),也包括海量的小文件(小于1MB)。特别是小文件的数量将达到千万级、亿级甚至十亿、百亿级。
在智能安防领域有很多典型的海量小文件场景,人脸识别就是其中之一。人脸识别的基础原理,就是通过将摄像机拍摄的图片与视图库进行比较,如果匹配则命中。对于一个大型城市来说,摄像机抓拍的图片数量会达到百亿级规模。在对这些原始数据进行分析应用的过程中就会涉及到对百亿级规模的海量小文件的处理。
类似的还有智慧金融,这也是一个会产生海量小文件的场景。金融业务不仅有大量原始票据通过扫描形成图片和描述信息文件,还有电子合同、签名数据、人脸识别数据等。金融的影像数据一般单个文件大小为几KB至几百KB不等,文件数量达到数亿至数十亿级规模,并且逐年增长,需要做长期的保存。
海量小文件,存储大烦恼
海量小文件体量庞大,但目前的文件系统包括本地文件系统、分布式文件系统都是匹配大文件场景的。从细节来说,如对元数据的管理、数据布局、缓存管理等的实现策略都侧重于大文件,导致在海量小文件情况下,存储处理性能极差。(比如日常的文件拷贝,如果拷贝一个大文件的电影到移动硬盘,拷贝的速度能达到100MB/S,但是如果拷贝的是超过上万个小图片,拷贝速度可能不到5MB/s)
因此,海量小文件存储问题一直被认为是工业界和学术界的难题,是海量数据时代上空飘着的那朵乌云。如前面所讲的智能安防、智慧金融的存储架构方案设计,就需要重点考虑到存储系统对于海量小文件的处理性能难题。
具体来说,导致海量小文件处理性能差的原因主要有如下三点:
元数据管理低效的问题
讲这个问题之前,我们先认识一下元数据。在存储系统中,数据分为两部分进行存储:一部分是真实数据;另一部分是描述这份数据的元数据,比如文件系统中文件的文件名、文件大小、执行权限等。元数据有着明显特点,那就是数量多,而且容量小。

在通用的文件系统设计中,如果需要访问一份真实的数据就需要先访问到该数据的元数据。可是我们知道,当前主流的文件系统基本都是面向大文件设计的,在海量小文件的情况下,因为必然会产生更大数量级的元数据,这会放大文件系统扩展性差、检索效率低的问题。比如传统NAS存储采用二叉树结构进行数据的存放,这种方法在遇到海量小文件的时候,文件系统在存储海量小文件的同时还需要存储更大数据级的海量元数据,NAS存储在扩展性和检索速度方面很容易就达到了瓶颈。所以,传统的NAS文件系统在海量小文件下,性能衰减得异常厉害,一般文件数量级到达千万级的时候效率就会变得极其低效。
因此,如果想要彻底解决海量小文件的问题,首先就需要存储系统有一个健壮高效的元数据管理平台(库)。如果没有核心技术解决这个问题,这个存储系统即使在其他方面的优化做得再好,也仅能满足几个亿级别的小文件存储,而无法满足百亿级别的小文件存储。
I/O访问流程复杂的问题
传统的文件系统在文件读写的时候流程过于复杂,在读取一个文件的时候,需要产生多次I/O。例如对于Linux系统在读取文件的时候,至少需要先读取文件目录元数据到内存,紧接着把文件的索引节点(inode)装载到内存,最后再读取实际的文件内容,在访问数据过程中会多次读取元数据,效率极低。
机械磁盘对于随机小I/O读写性能低
当前很多文件系统都是将元数据分散存储,从真实存储的位置来看分散在存储的所有磁盘当中,因此元数据的读写属于随机的I/O。然而机械磁盘对于随机的I/O性能极低,因此在海量小文件的场景下由于元数据读写会产生随机高频次的I/O读写,对于当前以机械盘为主的存储系统来说,性能极差。
(采用全闪存效果会比较好,但是目前来说,对于海量的非结构化数据若使用全闪存,从成本来看并不现实)
解决海量小文件存储难题
需要对症下药
综合上述分析,如果想要解决好海量小文件的存储难题,就需要对症下药。对于海量小文件的存储优化可以从元数据管理、数据组织、I/O 流程优化与缓存管理(业界通常称为Cache管理)等几个方面下手。具体的技术包括通过优化元数据管理与数据组织方式、小文件合并、优化缓存命中率等方面,来提升海量小文件的存储性能支撑,从而达到提升海量小文件访问效率的目的。
元数据的承载。正如上文所说,海量小文件处理的瓶颈在于对元数据的处理,业内通常采用分布式数据库实现。通过对元数据进行独立组织与承载,并通过元数据语义优化、写入优化等,降低元数据在I/O路径和资源等方面不必要的性能消耗与写入次数。匹配上优化的技术,减少I/O数量,比如在处理业务高并发的时候,将并发的多个操作合并成一个操作,进一步提升吞吐。最后,为了进一步保障元数据的小I/O高性能,通常将元数据存储在SSD的数据分层空间中,进一步加速元数据的访问效率。
分布式智能缓存技术。针对海量小文件设计的分布式智能缓存层,能够让小文件在写入SSD后即返回,缩短I/O路径,有效降低时延,提高性能。同时还可以有效降低原生纠删码的I/O写入放大的问题,提高原生纠删码的性能,进一步提升分布式存储对海量小文件的性能支持。
小文件合并。通过将小文件落在智能缓存的同时还能够将小文件在线合并成大I/O,然后通过条带化技术(将大数据切分成小数据并发存储到不同硬盘)写入HDD,极大地提升了I/O的性能。并且小文件合并还能够减少文件数量,从而减少对应的元数据数量,来提升性能。
行业难题与机遇往往相伴而行,各大厂商在攻克海量小文件存储难题上各显神通,既有老牌厂商,也有近年来异军突起的新锐玩家。在这其中,深信服存储宛若一个老道的新手,在海量小文件的处理上携清晰的解题思路强势入局。根据深信服公开的技术资料来看,其EDS对企业级分布式存储处理海量小文件的性能优化思路与前面讲的几点不谋而合,其核心技术点可以归纳为三点:
第一,深信服推出了一个全新的分布式数据库PhxKV来对独立承载元数据。PhxKV具备优秀的性能扩展能力,能够轻松承载数百亿规模的元数据,成为深信服支撑百亿海量小文件高性能的坚实基础。深信服内部进行的性能测试显示,PhxKV使用两核时的吞吐,就能和MongoDB使用17核时的吞吐相当。
第二,通过智能缓存技术,采用高性能的SSD来加速海量小文件的读写效率并缩短I/O路径。
第三,通过小文件合并技术来降低文件的数量,从而减少整体I/O读写频次来提高I/O性能。
尤其是针对海量小文件的顽疾,深信服企业级分布式存储EDS在性能提升方面表现抢眼,并且在权威机构测试和用户的实际应用中得到检验。
日前,深信服企业级分布式存储EDS通过中国泰尔实验室权威机构多项指标测试验证,其中对海量小文件承载的性能表现很抢眼。根据测试数据,深信服EDS通过三节点构建的对象存储能够轻松承载100亿小文件,且性能抖动不超过5%;对象上传速度达到15,000个/s,对象下载速度达到40,000个/s。
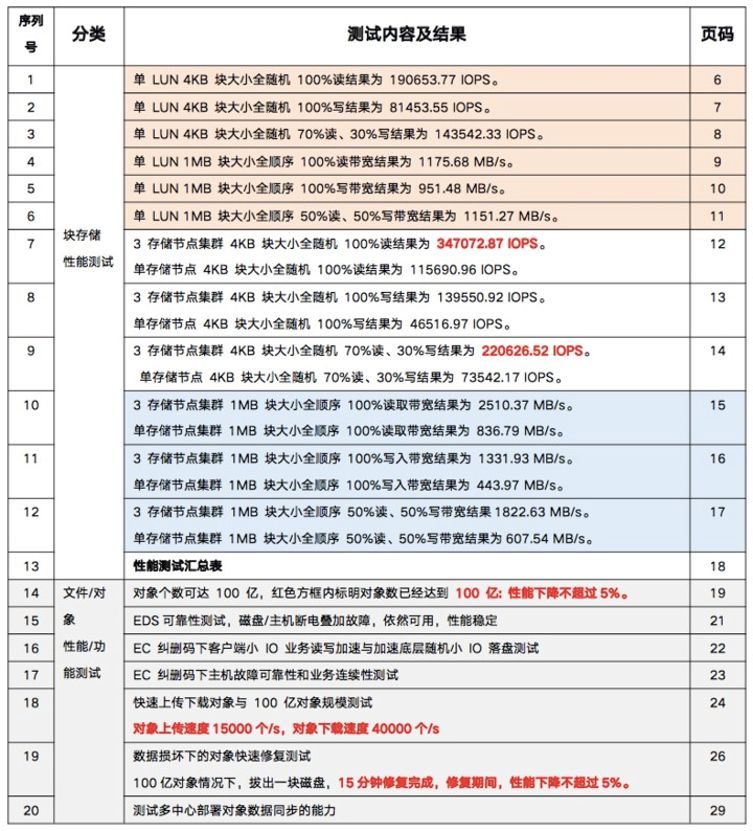
▲深信服EDS中国泰尔实验室测试内容及结果
值得一提的是,深信服EDS在处理海量小文件时呈现出的高性能,是通过软件机制和优化来充分发挥硬件长处、激发硬件潜能,最终实现用更低成本的硬件平台,也能够获得高性能,带来的是更具性价比的解题思路。
海量小文件实践案例
南方某市公安系统采用了深信服分布式存储进行智能安防的数据存储,其中涉及到3.5PB的视频存储以及数十亿级别的人脸识别的海量小文件存储,是一个典型的大文件与海量小文件混合存储的场景。
深信服企业级分布式存储EDS采用对象存储与平台进行对接,系统峰值每秒有将近3,000张图片写入存储系统。目前存储系统内保存的海量小文件数量已经超过50亿,而且还在不断增长当中。得益于深信服在海量小文件的性能优化,使得EDS平台能够从容应对大并发的人脸识别系统,并且满足后续针对原始图片数据的二次挖掘应用。
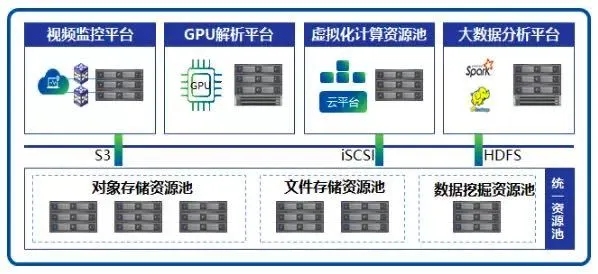
对于非结构化数据存储来说,攻克了海量小文件存储难题,基本代表了该存储能够适配绝大多数非结构化数据存储的场景。深信服分布式存储基于软件定义技术、采用通用的X86服务器与以太网交换机,激发硬件潜能,在海量数据时代帮助用户构建一个可靠、高性能、智能管理的海量数据存储平台。
关于深信服新IT
深信服基于软件定义重塑IT基础架构,为用户提供敏捷、智能、安全的新一代IT基础设施,包括桌面云aDesk、应用交付AD、软件定义广域网SD-WAN、企业级分布式存储EDS等。深信服打造的新一代IT基础设施解决了传统基础设施面临的效率低、成本高、安全性差等一系列问题,加速用户的数字化转型进程。