大国之间的复杂博弈使得当代战争复杂性急剧增加。在此背景下,2022年2月,美兰德公司发布《模拟仿真和兵棋推演中的人工智能》报告,讨论了人工智能(AI)如何应用于政治、军事的模拟仿真和兵棋推演中;提出了三个主要观点:模拟仿真和兵棋推演是相互关联的研究方法,应该一起使用;AI可以对每一种方法做出贡献;用于兵棋推演的AI应该由模拟仿真提供信息,而用于模拟仿真的AI应该由兵棋推演提供信息。
模拟仿真、兵棋推演的区别与联系
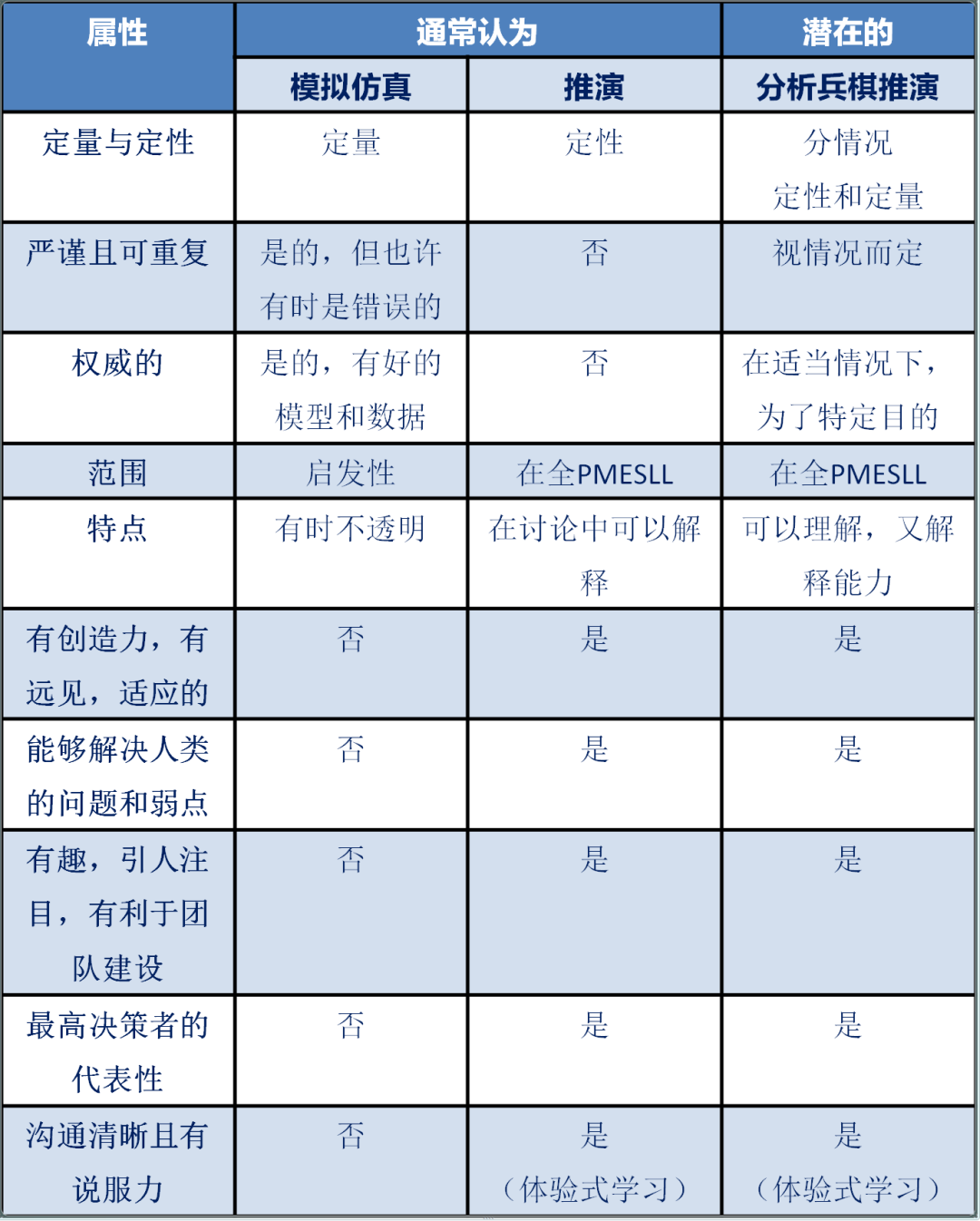
模拟仿真、兵棋推演有不同的优点和缺点,如表1所示。模拟仿真重在“定量”,但由于未能反映人的定性考虑而受到极大限制。有的批评者认为模拟仿真的“严谨”所产生的结果虽然是精确的,但却可能是错误的,而兵棋推演则可以纠正这些缺点。
表1 模拟仿真和兵棋推演之间的差异
兵棋推演处于同样受争议的境地。一方面,兵棋推演的各方面成就使得模拟仿真受益匪浅;另一方面,兵棋推演的质量参差不齐,有的纯粹是浪费时间,有的是与事实完全相反的结果,有的则能提供独到、丰富的见解。
该报告认为,应该综合运用两种方法。如图1所示,随着时间的推移,从模拟仿真和兵棋推演中获得的经验被吸收借鉴,使用人工智能从模拟仿真实验中挖掘数据(第4项),以便为后续的过程补充完善理论和数据(第5项)。在任何时候,根据问题定制的“模拟仿真-兵棋推演”模型可以解决现实世界的问题(第7项)。如同在浅灰色的气泡中,人类团队的决策辅助工具(项目6a)和主体(Agent)的启发式规则(项目6b)被生成和更新。有些是直接构建的,但其他的是从分析模拟仿真实验和兵棋推演中提炼出来的知识。该报告认为这个综合模型与专注于一个或几个单一模型形成鲜明对比,总体上来说是具有革命性意义的。
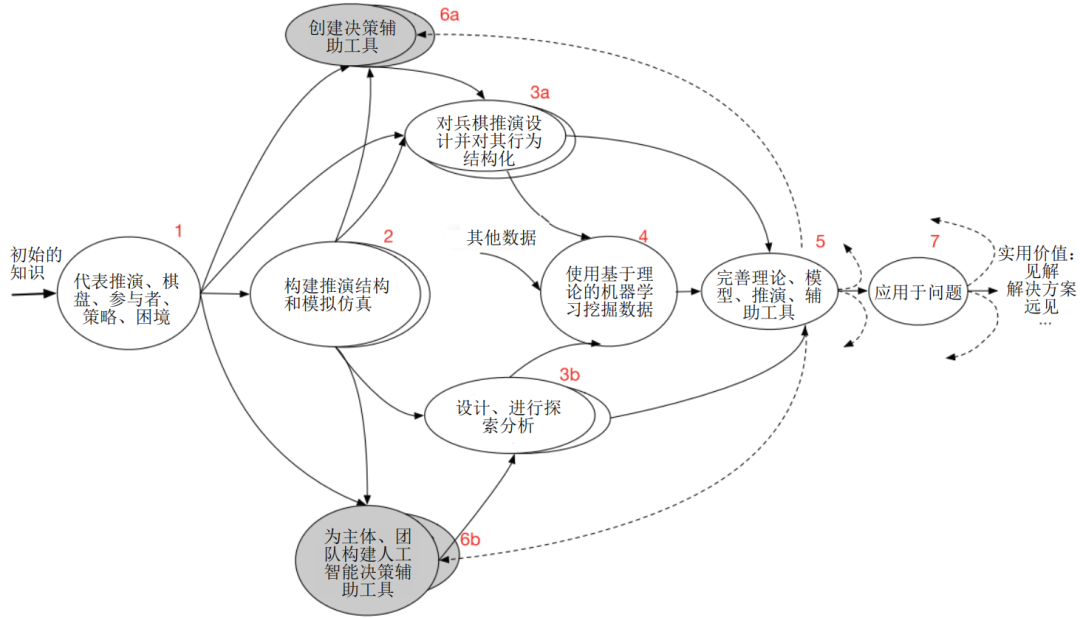
显示了一个相应的愿景
大国之间复杂博弈带来认知复杂性
该报告认为今天的国际安全挑战远远超出了冷战时期的挑战,各国迫切需要新的兵棋推演和新的军事战略。
多极化和扩散。该报告认为世界现在有多个决策中心,它们的行动是相互依赖的。从概念上讲,这将人类置于多体博弈论的世界中。但是由于各种原因,多体博弈论解决方案的概念没有被广泛采用。尽管目前在战略稳定方面已经做了一些努力,但现实世界的多极化可能太复杂而导致无法建模。随机混合策略通常在多体博弈中的作用很小。同样,在计算其他参与者的行动时可能存在更多的内在复杂性,以至于随机化产生的额外一层不确定性对我们理解未来的危机动态几乎没有帮助。
多维战争。相比1980年,现在拥有大规模杀伤性武器的国家更多。网络作为一种战略武器的加入使事情变得更加复杂。武器装备的变化扩大了高端危机和冲突的维度,如远程精确打击和新形式的网络战、信息战和太空战。
有限高端战争的可行性。一个未被充分认识的推论是,世界现在比以前更适合有限的高端战争,在这种战争中——尽管更热衷于威慑理论的人观点相反——可能会有博弈中的赢家和输家。旷日持久的“有限”战略战争现在极有可能发生。
盟友之间相互冲突的目标。该报告认为,今天的美国盟友有着不同的重要利益和看法。北约在整个冷战期间表现出的非凡的团结,在现代危机或冲突中可能无法重现。在亚太地区,相关国家之间的矛盾关系构成了危机中困难的预兆。所有这些国家都有通过使用太空、网络空间或区域范围内的精确武器进行升级的选择。该报告认为,人类可能正在进入一个类似于20世纪初的多极化阶段。
各类新兴技术给建模问题带来机遇
各类新兴技术在各领域的广泛应用,给国家安全相关的建模问题带来了新的机遇。典型的新技术包括如下几个。
基于主体的建模。基于主体的建模(ABM)已经取得了很大的进展,并且对于提供现象如何展开的因果理解的生成建模尤其重要。这种生成模型是现代科学的革命性发展。与早期专家系统的主体不同,今天的主体本质上是典型的目标寻求或位置改进,这可能使它们更具适应性。
模块化和专门构建的模型组合。现在,构建独立有用的模型(如模块)并根据问题的需要组成更复杂的结构是有意义的。模块化设计允许对正在建模的内容进行替换,这可以开阔思维,避免意外或为适应做准备。此外,模块化开发有助于插入针对特定问题的专门化,这是建模师和分析师团体在2000年中期美国防部研讨会上推荐的方法。
数据驱动的AI/机器学习。人工智能这个术语现在通常用来指机器学习(ML),它只是人工智能的一个版本。最大似然法已经有了很大的进步,最大似然法模型在拟合过去的数据和发现其他未被认识的关系时经常是准确的。
深度不确定性下的决策。在“深度不确定性下的决策”主题下,讨论的规划概念和技术已经发生了根本性的进展(DMDU)。在许多不确定的假设中,预期表现良好的策略。尽管在过去,不断增加的不确定性常常令人麻痹,但今天却不必如此。这些见解和方法在国防规划和社会政策分析中有着悠久的历史,应该被纳入人工智能和决策辅助。
设计“永不停机”的智能系统。从技术上来说,大多数国防部的“模拟仿真-兵棋推演”模型被人工智能称为“转换”。模型或游戏有一个起点,它运行,然后报告赢家和输家。可以进行多次运行并汇总结果,以捕捉复杂动力学中固有的变化。新的人工智能模型设计不同,模拟“永远在线”的系统。这被称为反应式编程,不同于转换式编程。这些系统从未停止,也不只是将输入数据转换成输出数据。
“AI+模拟仿真+兵棋推演”新模型
该报告为构建一个完整的“AI+模拟仿真+兵棋推演”架构给出了相关建议。图2勾勒了一个顶层架构,在考虑许多可能的危机和冲突时,需要深入关注至少三个主要的行为者,以解决当前时代的危机和冲突。图2还要求对军事模拟采取模块化方法。
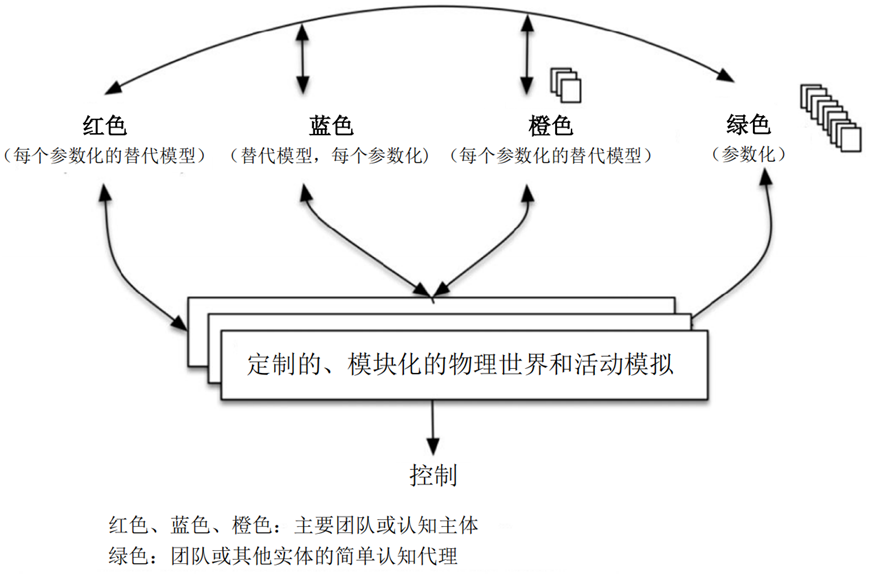
多方博弈结构模拟
该报告认为,为大规模情景生成、探索性分析和不确定性下的决策做准备是必要的,需要强调两个重要问题:第一,只有当模拟在结构上是有效的(即模型本身是有效的),不同参数值的探索性分析才是有用的;第二,从探索性分析中得出结论是有问题的,因为所研究的案例(方案)的可能性不一样,它们的概率是相关的,但没有分配概率分布的良好基础。
模型的有效性和数据的有效性应该分别用于描述、解释、后预测、探索和预测。参数化方法有很大的作用,但模型的不确定性经常被忽视,需要更多的关注。
结语
综上所述,该报告认为模拟仿真和兵棋推演是相互关联的研究方法。在“AI+模拟仿真+兵棋推演”模型中,用于兵棋推演的AI应该由模拟仿真提供信息,用于模拟仿真的AI应该由兵棋推演提供信息。需要指出的是,该模型仍将是不完美的,但却有可能提高决策的质量。