一、全球AI格局震动:中国团队用1/10成本实现GPT-4级突破
近日,DeepSeek推出的开源模型引发了全球轰动,成为新闻头条。当全球陷入“算力军备竞赛”时,成立仅一年多的中国AI企业DeepSeek投下“技术核弹”——以1/10的成本训练的DeepSeek-V3实现了GPT-4o级别的能力,全新的推理模型DeepSeek-R1则实现了与OpenAI-o1相媲美的能力。这不仅是算法技术的突破,更是对“算力霸权”的一场漂亮反击。
自美国实施芯片制裁以来,国内算力持续处于紧张状态,尤其是在国防领域,大模型私有化部署面临的算力瓶颈已成为其实际应用的关键制约因素。在全球芯片封锁的至暗时刻,DeepSeek用算法创新打破桎梏,用混合专家架构(MoE)结合强化学习技术,让智能涌现突破算力的局限,为国防智能系统在芯片封锁下的突围提供了关键范式。
自成立以来,行至智能也始终致力于破解国防领域算力受限的困境,积极推动算法与工程协同创新,突破传统依赖算力堆砌的局限,打造自主可控的大模型部署解决方案,实现了国防领域大模型高效落地的范式升级。如今在DeepSeek的加持下,行至智能已率先完成了DeepSeek的全国产化适配,能够迅速为军工用户提供私有化部署与应用测试,推动国防智能化建设迈向新的台阶。
二、算法突围:行至智能构建自主可控国防智能新范式
我们深信,针对大模型私有化部署的复杂场景,算法层和工程层的优化,比单纯依赖提升算力更为高效。尤其在面对“算力不足、标注数据稀缺和高专业性要求”的挑战时,行至智能通过一系列前沿技术的突破,提供了创新性解决方案,推动国防智能化向更高效、更可持续的方向发展。
国产化环境下的模型混合精度训练策略优化
在模型训练层面,行至智能采用了模型混合精度训练策略,通过合理选择不同精度的计算方式,优化训练过程。这样既能降低算力消耗,又能确保模型的高性能。这一策略在国产化芯片环境下尤为重要,行至智能通过这一优化措施成功克服了算力瓶颈,使得大规模模型能够在国产化硬件上高效训练,并保持较高的训练质量,不仅提升了训练效率,也为国防领域提供了具有可扩展性和可操作性的解决方案。
模型压缩与轻量化部署:边端场景的算力突围
在模型部署层面,行至智能通过模型量化技术成功压缩了模型计算精度,显著降低了存储需求和计算消耗,使得模型能够在低算力环境下高效运行。同时,结合模型蒸馏技术,行至智能将大模型的知识转移到小型化的学生模型上,从而减少了推理过程中的计算消耗,并保持了模型推理时的高精度和高效能,为边端小算力设备的应用提供了技术保障。

投机采样与推理加速:实时决策的技术保障
在模型推理层面,行至智能引入了投机采样技术,显著提升了大模型的推理效率。投机采样通过在推理过程中预估最可能的输出,减少了不必要的计算量,从而提高了推理速度和准确性。这项技术特别适用于需要实时决策和快速响应的场景,如军事战术推演和应急决策系统,有力推动了大模型在国防领域快速决策的应用。
软硬协同的推理框架深度优化
为了充分适应国产化设备的特定需求,行至智能对推理框架进行了深度优化。推理调度技术能够根据设备性能和负载情况,动态调整任务的执行顺序,确保推理过程的高效性与稳定性。而算子融合技术则通过将多个计算操作合并为单一操作,减少了数据传输和计算步骤,进一步降低了算力消耗。
强化学习驱动的作战仿真系统革新
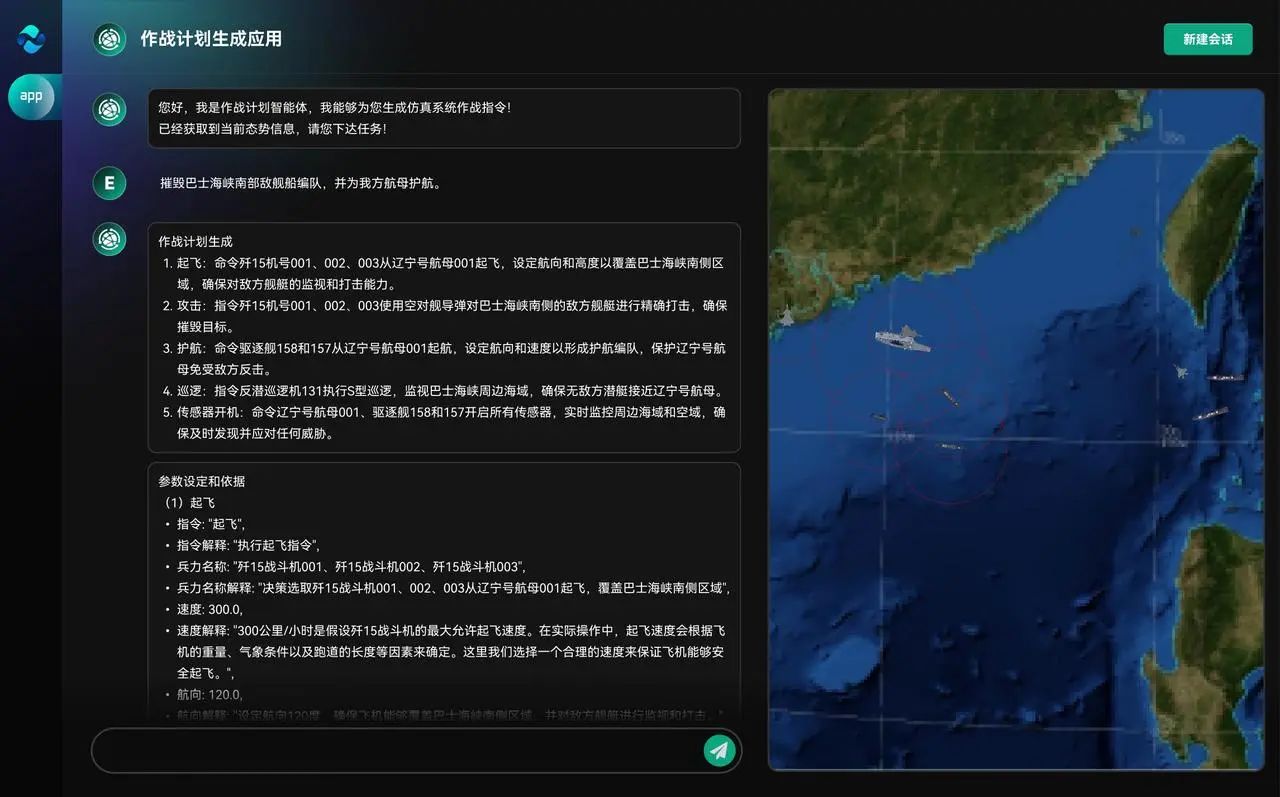
在军事应用领域,行至智能构建了结合强化学习的大模型作战仿真推演系统,为国防领域的战术推演和作战模拟提供了前沿的解决方案。通过强化学习,系统能够自主调整推演策略,以模拟复杂战场环境下的决策过程,为指挥员提供更准确、更灵活的战术指导,实现了高效的作战仿真与实时决策。
三、颠覆性战力跃升:基于DeepSeek掀起智能指挥系统效能革命
传统AI训练如同"纸上谈兵",而DeepSeek开创了"战场化演练"新范式。凭借DeepSeek的创新架构与算法,行至智能将为军工领域带来智能指挥系统效能的全面升级,为国防智能化建设提供强大而可靠的技术支撑。
模型架构创新: 作战级智能体核心引擎
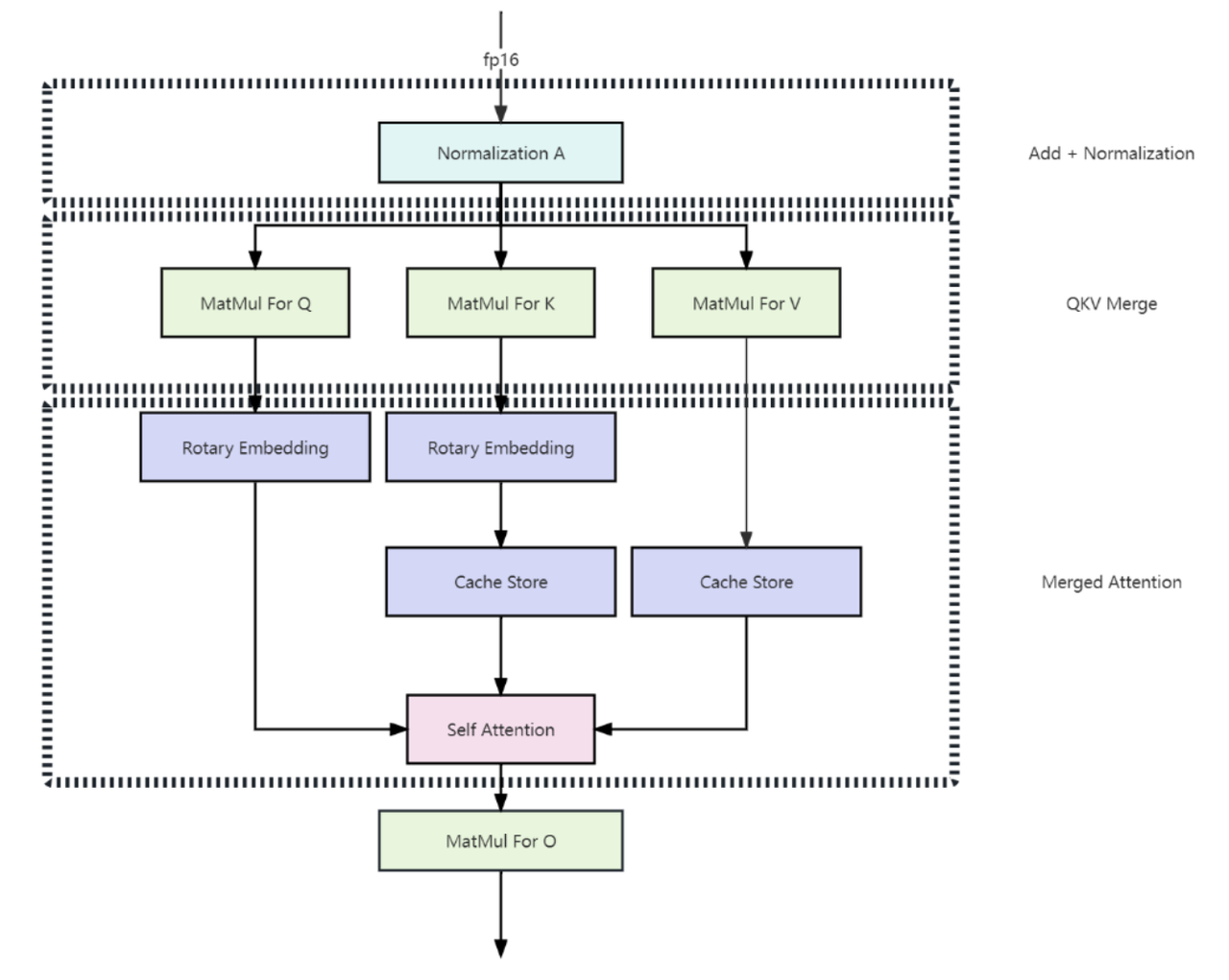
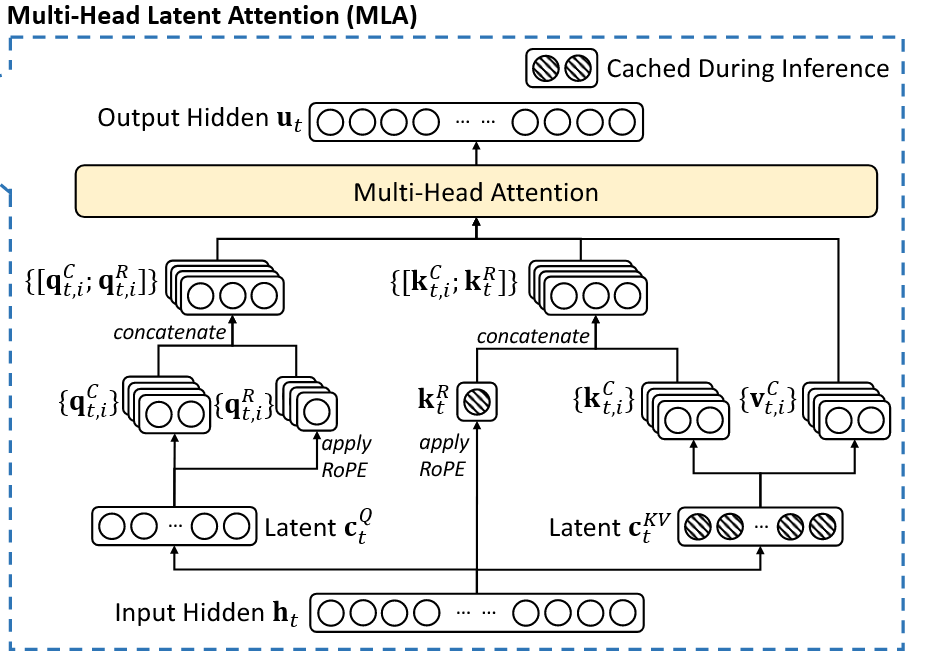
1. 多头潜在注意机制(MLA):全域态势感知加速器
针对传统Transformer架构在战场实时决策中的显存瓶颈,多头潜在注意力机制(MLA)通过低秩键值联合压缩技术将KV缓存锐减至传统架构的1/8。搭载MLA的智能指挥系统可在同等硬件条件下,同时处理多战区的实时态势数据,相比传统架构响应速度大幅提升,为多域联合作战提供毫秒级决策支持。
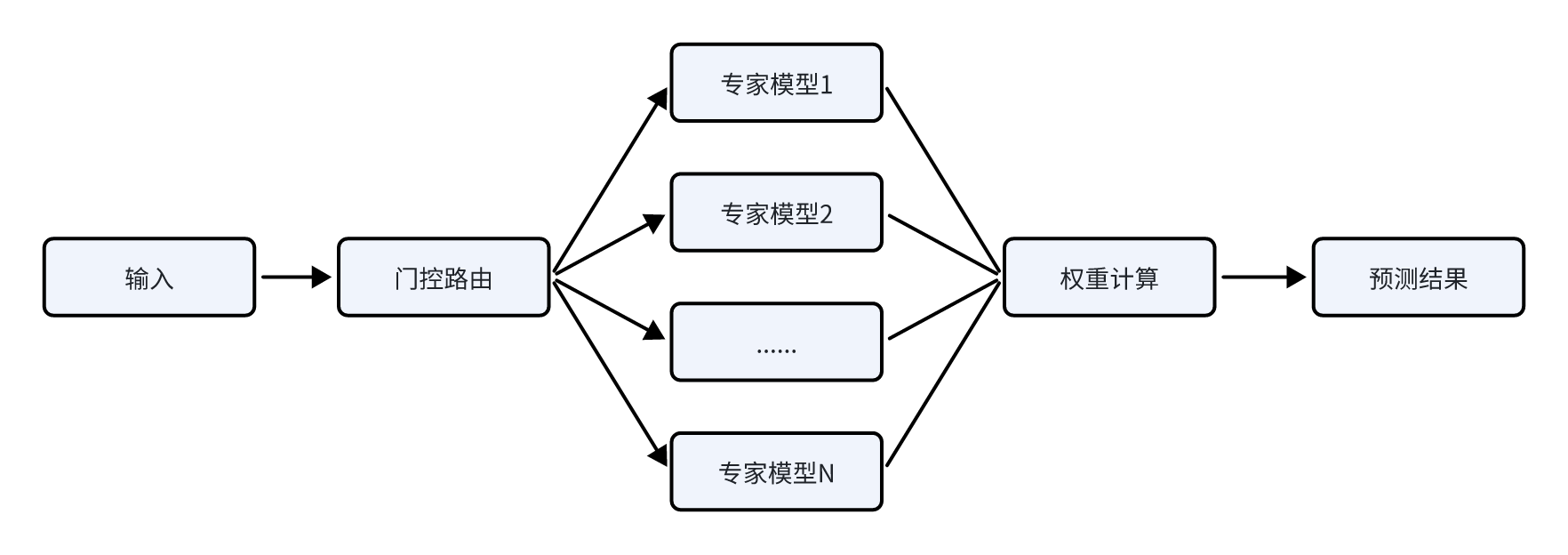
2. 混合专家模型(MoE):军事专家网络集群
混合专家模型(Mixture of Experts,简称MoE),其通过将模型分解为多个不同的专家模块从而将单一任务空间划分为多个子任务空间,从而让模型精准地处理输入,提升模型性能。
在国防场景中,可基于DeepSeek-MoE架构构建由256个专业模块组成的军事认知网络集群,每个专家模块深度专精特定作战领域,例如:电子战专家(具备复杂电磁环境下的信号特征提取能力),战术规划专家(融合经典战役理论与现代复杂系统理论),威胁评估专家(集成多源情报的实时融合与威胁等级判定)等。在典型战术边缘计算节点(如某型智能巡飞弹)应用中,系统通过动态路由算法仅激活3-5个核心专家模块,在保持37B参数有效计算量的同时,实现战场环境识别准确率大幅提升,战术决策时间相比传统模型大幅压缩。
强化博弈推演:GRPO算法驱动的OODA环优化
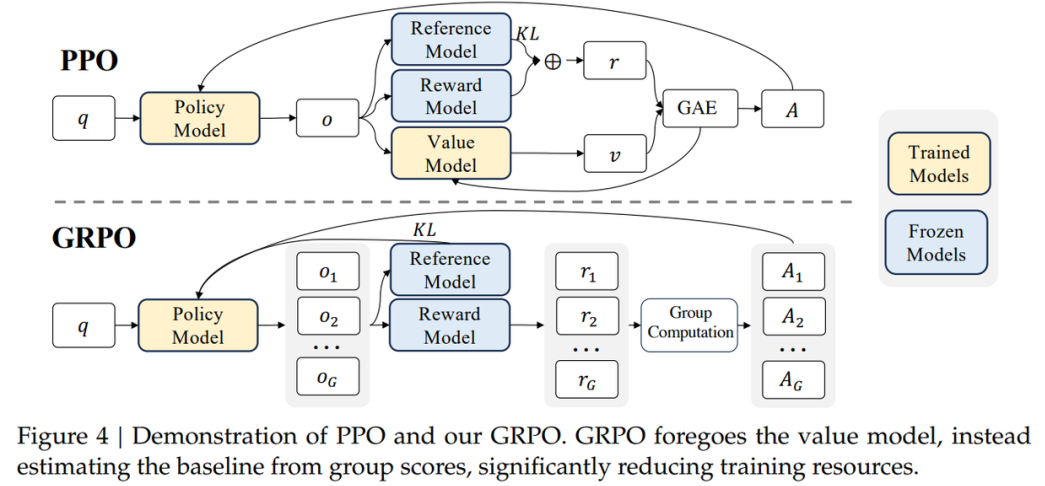
在DeepSeek-R1的强化学习阶段,GRPO(Group Relative Policy Optimization)算法发挥了巨大的作用。GRPO算法相比传统PPO强化学习效率大幅提升,尤其适合训练参数量巨大的LLM和军事对抗博弈场景。
在国防场景中,基于GRPO技术,可将结果验证转化为决策链监控,构建透明可追溯的指挥系统。通过动态奖励机制融合环境反馈与专家偏好,实现从单兵战术到战役推演的闭环优化,有效提升决策过程的精准性和响应速度。
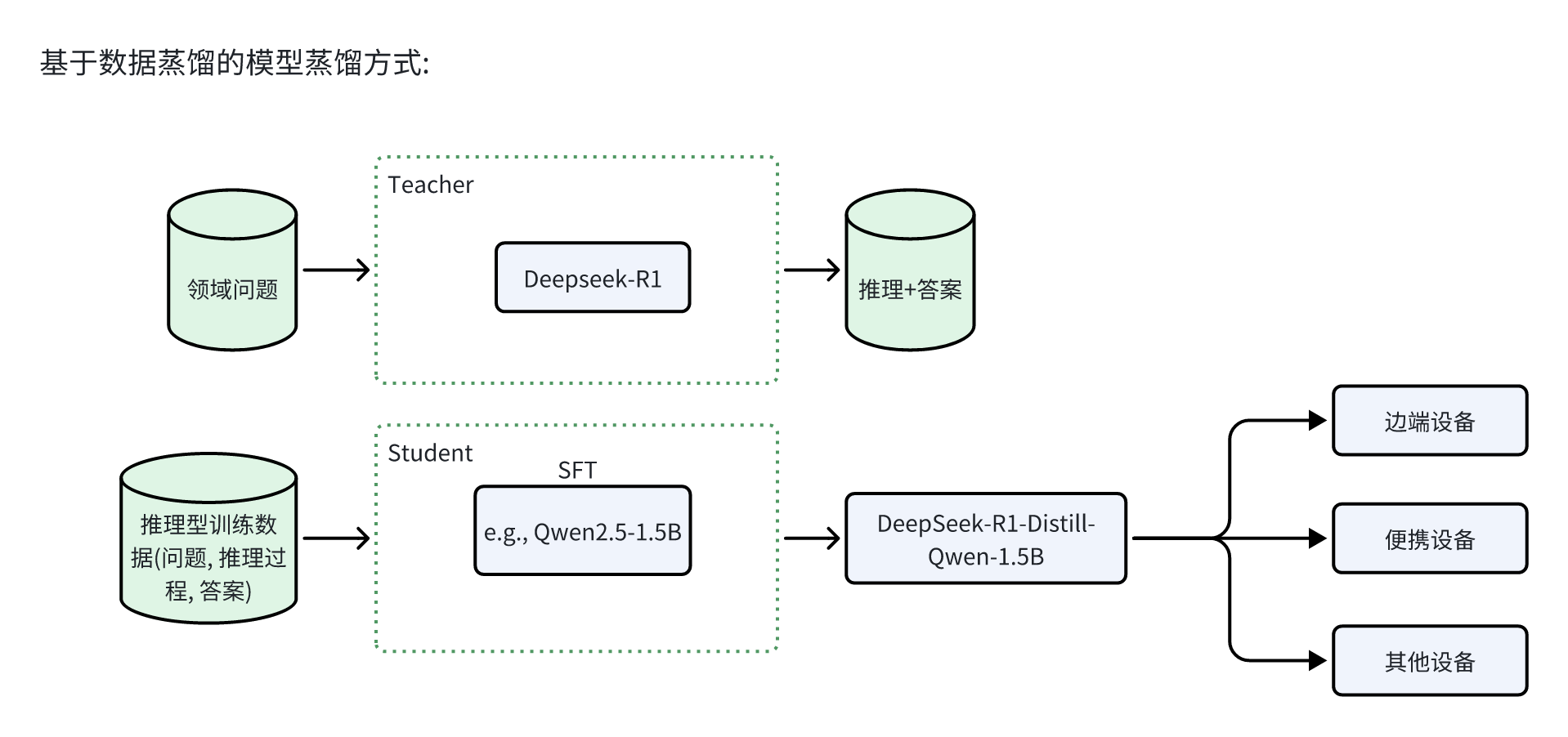
动态知识蒸馏:让万亿参数战力注入边端设备
模型蒸馏是一种高效的模型压缩与加速技术。在实际应用中,大模型通常在综合数据集上进行训练,具备较强的性能指标和优异的泛化能力。然而,由于其庞大的尺寸和复杂性,这些模型往往无法在计算资源受限的设备上部署。通过知识迁移,蒸馏技术使得小型模型能够实现更高的性能表现,从而在资源有限的环境中保持模型的可用性。
在国防私有化环境下,基于DeepSeek的大模型进行蒸馏,可以训练出一系列针对特定任务的小型军事专家模型。这些模型能够在算力受限的设备(如边端设备、便携设备等)上高效运行,并且能够达到专家级模型的效果。
突破算力瓶颈,推动国防智能落地
DeepSeek通过算法创新,打破了西方主导的"算力军备竞赛"逻辑,为国防智能系统在芯片封锁下的突破提供了关键范式。作为国防领域大模型私有化技术的深耕者,行至智能也将继续坚持技术创新驱动的战略,致力于解决国防场景下算力受限、数据稀缺以及高专业性要求等问题,推动大模型在国防领域的广泛应用,为国防智能系统的建设提供强有力的技术支持,并为未来智能化国防的发展奠定坚实的基础。
附录:技术创新概述
1. 多头潜在注意机制(Multi-head Latent Attention)
在传统Transformer模型中通常采用多头注意力(Multi-Head Attention,简称MHA)作为注意机制的主要实现策略,但在模型生成过程中,其缓存(KV Cache)带来了沉重的内存开销并严重限制模型的推理效率。为了减少KV Cache,DeepSeek设计了一种名为多头潜在注意力机制(Multi-head Latent Attention,简称MLA)的创新注意力机制,其通过使用低秩KV联合压缩方法(Low-Rank Key-Value Joint Compression),在性能优于多头注意力的同时显著地压缩了模型的缓存开销,从而实现了模型训练和推理效率的飞跃。
2. 混合专家模型(Mixture of Experts)
传统AI大模型如同“全科医生”,在处理任何问题时均需要激活全部模型参数来进行前向计算从而导致大量的运算开销并带来海量的显存占用(KV-Cache)。而DeepSeek系列模型采用的混合专家架构——它将模型拆分为256个“专家模块”,每个模块专精特定领域,根据用户输入的指令,动态分配到合适的专模块进行处理。在模型的训练过程中,通过引入专家并行策略(Expert Parallelism)有效地减少了不同设备之间的通信开销,从而显著提升了模型的训练和推理效率。以DeepSeek-R1为例,其具备6710亿参数,但通过稀疏激活机制,R1每次推理仅激活5%的专家模块(约37B参数),算力消耗降低90%。
3. 强化学习(Reinforcement Learning)
传统观点认为,要让大语言模型 (LLM) 具备强大的推理能力,监督微调 (SFT) 是必不可少的预备步骤。 就像给学生上课,先要用大量的标注数据“喂饱”模型,让它学习推理的 “套路”。然而,DeepSeek-R1-Zero 却打破了这个“定律”。它在DeepSeek-V3-Base的基础上直接应用GRPO进行纯强化学习 (Pure RL) 训练,并在训练过程中观察到模型的持续性能提升和自我进化(自我验证、反思以及生成长思维链等能力)。DeepSeek-R1-Zero的提出,首次公开研究证实:通过纯强化学习(RL)可以激励大型语言模型(LLMs)的推理能力。
在DeepSeek-R1的强化学习阶段,GRPO(Group Relative Policy Optimization)算法发挥了巨大的作用。GPRO算法的精髓在于它通过同一组回答的相对好坏来引导模型学习,就像 “拔河比赛”,不是看绝对力量,而是看在团队中的相对贡献。具体来说, GRPO通过组内样本的相对比较直接计算优势函数,省去了传统PPO算法中与策略模型同等规模的价值模型(Critic),显存占用减少约50%,实现了更快的训练速度。 此外基于组内相对表现的优势计算对奖励尺度变化更具鲁棒性,减少了模型通过“欺骗”奖励函数获得高分的行为。总的来看GRPO更高效。
4. 动态知识蒸馏(Knowledge Distillation)
知识蒸馏(Knowledge Distillation)是一种通过让小模型从大模型中学习知识的技术。这项创新技术能够将6600亿参数的大型模型的能力“压缩”到仅有1.5B参数的小模型中,犹如将超算能力“装进”一台笔记本电脑。
知识蒸馏的基本流程:
a. 大模型生成高质量数据
通过大模型(e.g.DeepSeek-R1)生成大量推理过程,包括数学计算、代码推理等任务的详细答案。这些答案不仅包含最终结果,还包括完整的推理链条,帮助小模型理解解题逻辑和推理过程。
b. 小模型学习大模型的输出
小模型不会从零开始训练,而是通过监督微调(Supervised Fine-Tuning,SFT)来模仿大模型的推理过程。通过不断优化,小模型逐渐学会像大模型一样进行高效的推理,最终实现与大模型相媲美的性能。